
15 September 2020
Tips and tricks of a first year data analyst

There were a lot of things that I wish I knew a year ago, when I took my first steps as a data analyst. With data requirements constantly changing, it can be difficult to know where to start when beginning your analytics engineering career. So, if you are new to all this, I hope this list of tips and tricks that I have acquired along the way will help make your first year a success.
Know your toolset
You need to utilise a lot of different tools working in this field, and while everyone has their own workflows, it is critical to understand the tools you are using to the best of your ability.
I have used various tools so far, and there are some particularly important ones I would like to cover.
Git
Git is used for version controlling your codebase, which in my opinion, is totally invaluable. Not only is the code stored in the cloud, preventing work loss if your machine kicks the bucket, but it allows team members to access the code and make their own changes to it. Additionally, it enables other tools to read specific versions of the codebase and operate using different environments. The key takeaway - it will save you a lot of headaches as your project gets bigger and more people get involved.
What exactly is version controlling? It is actually rather self explanatory, in that you have the ability to control different versions of code. You can specify which version of the code is in production, and which versions are in development. It also provides a layer of safety in the event the latest production code has any issues - you can simply roll back to an older, stable version of the code while you fix the issues in the newer code.
Now, while Git can be extremely convoluted and difficult to master, it is relatively easy to pick up the basics. There is a lot of documentation available to support you through your Git adventures.
My top Git tips are:
- Always make a new branch to work on - never commit directly into Master or a Release branch
- Commit your changes frequently
- Make a new branch for every major change to the codebase. Do not alter multiple sections of the codebase on the same branch
- Always check that your local Master branch is up to date before creating a new branch
- Get someone to review your pull requests, two pairs of eyes are always better than one
- Run all of your tests before you commit your changes, if they fail, fix your code
dbt
Data Build Tool (dbt) is used for a variety of purposes including compiling models in data warehouses, running tests on those models, creating macros and automating the compilation of models using dbt Cloud. Most importantly, you can create multiple environments for development and production, allowing you to keep working on a project after it has been launched, without breaking the production version.
Automation
Having the ability to automate models in platforms like BigQuery opens up the doors to advanced data transformation for reporting in dashboarding products such as Data Studio. While Data Studio has its own set of direct connections to various platforms, the ability to transform data is very limited. Automation negates this limitation as you no longer need to lean on the direct connectors.
Using BigQuery to transform your data is far superior to Data Studio’s calculated metrics, but it can be overkill for some projects.
My advice… build a wireframe.
A wireframe is essentially a sketch of the final product. It should outline the key features and how you would expect them to work. Using a wireframe helps you to prototype ideas without having to develop the data pipeline. Once you and the client are happy with the wireframe, then you can begin building the data pipeline.
With a completed wireframe, you will be able to analyse the requirements of the product. This will allow you to better understand whether the limitations of the direct connectors will restrict the feasibility of the project. If so, move straight to BigQuery. Alternatively, if you are reporting on more than one platform and intend to have a top level view, don’t bother with the direct connectors as there is no UNION for data blending in Data Studio.
Keep it DRY
Don’t repeat yourself (DRY) is a philosophy carried through the entire coding world. This is another area where our hero, dbt, comes to save the day… macros!
dbt’s macros allow you to write code and reference it in other models. This can be extremely useful for generating unique row IDs, casting data in the correct format, or for staging queries in general.
One particular issue I had to overcome was inconsistent date formats from my source data. To remedy this, I wrote a macro that converted the two date formats in the dataset into YYYY-MM-DD.
/* Corrects date format from ISO 6801 to YYYY-MM-DD */
{% macro date_fix( date_col ) %}
{% if date_col is not defined %}
{% set date_col = 'date' %}
{% endif %}
case
when {{ date_col }} like '%-%' then parse_date_col('%Y-%m-%d', {{ date_col }} )
else date_col_add( '1899-12-30', interval safe_cast( {{ date_col }} as int64) day)
end as {{ date_col }}
{% endmacro %}
This macro is called using {{ date_fix('date') }}, which is far quicker than replicating the case statement in the macro.
The only way, I think, that you can take macros too far is when there is no code in any of the actual models. My advice is:
- If you’ve typed the same line of code twice already, make it a macro
- Save reusable macros in a ‘developers toolkit’ repository to save yourself and your team time later on
Working environments
Working environments are areas for you to develop and test code in. dbt allows for multiple working environments - we only use two, one for development and one for production. That said, you can create as many environments as you see fit.
Why should you have more than one working environment? The most common reason is to segregate development and production. This permits you to continually develop new versions of a product one it has been launched without breaking the production version.
For web development it might even make sense to use three environments:
- Staging new changes
- Development site
- Production site
This provides teams with the freedom to work on their own sections of the site in staging, merge all of the changes into development to get a good look at how the final product will look, then push the changes to production when happy with the development site.
Tips for managing working environments:
- No version control is a disaster waiting to happen so, keep old production versions available to fall back on should a breaking bug slip through testing
- Do not test new code in production - you will break something
- Get someone else to review and test your code before you push to production
- Set a strict process for pushing changes into production and make sure everyone adheres to them. The last thing you want is rogue code that doesn’t work plaguing your previously functioning product
Shell is your friend
While many of your tools may have their own websites or applications with a sleek and easy to use UI, using the command-line interface (CLI) can often be a far more efficient method to utilise them.
While the CLI versions of these tools can seem like a steep learning curve, every tool has its own documentation. Not only can you find documentation online, but for a quick lookup, try appending -h or --help to your command. This will open a help page in your shell which will list all of the variables and a description of what they do. Alternatively, using $ man tool-name will open documentation on the tool, however this will not work for every tool.
Shell is extremely powerful for navigating and parsing files on your machine. Using shell commands such as head and tail can be useful in parsing .csv files. I highly recommend learning some basic shell commands as it will significantly increase your efficiency in many tasks.
T-shaped knowledge
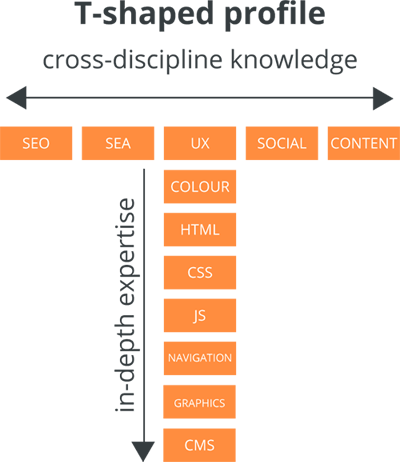
Image taken from Benjamin Slap’s article - “The rise of technical marketers”
The philosophy of a ‘T-shaped’ knowledge base is that you specialise heavily in one particular thing, but are able to branch out to other areas, often related to your speciality. As an analytics engineer, it is not enough to only understand your toolset and utilise it effectively. You must also understand the data you are working with and be able to draw valuable insights from it.
Knowing your data sources
There are hundreds of possible data sources in the digital marketing world, from all of the social platforms, to the Google Marketing Platform (GMP). There are many common reporting metrics and dimensions between them, but most platforms have dimensions and metrics that are incompatible. For example, action type is not compatible with impressions and clicks data in Facebook reporting.
In the data blend below, we are joining more standard Facebook metrics, with Facebook “Actions” data. Importing the data using two datasets allows you to build filters on the “Actions” using “Actions Type”. You can then join them together to create a consolidated dataset.
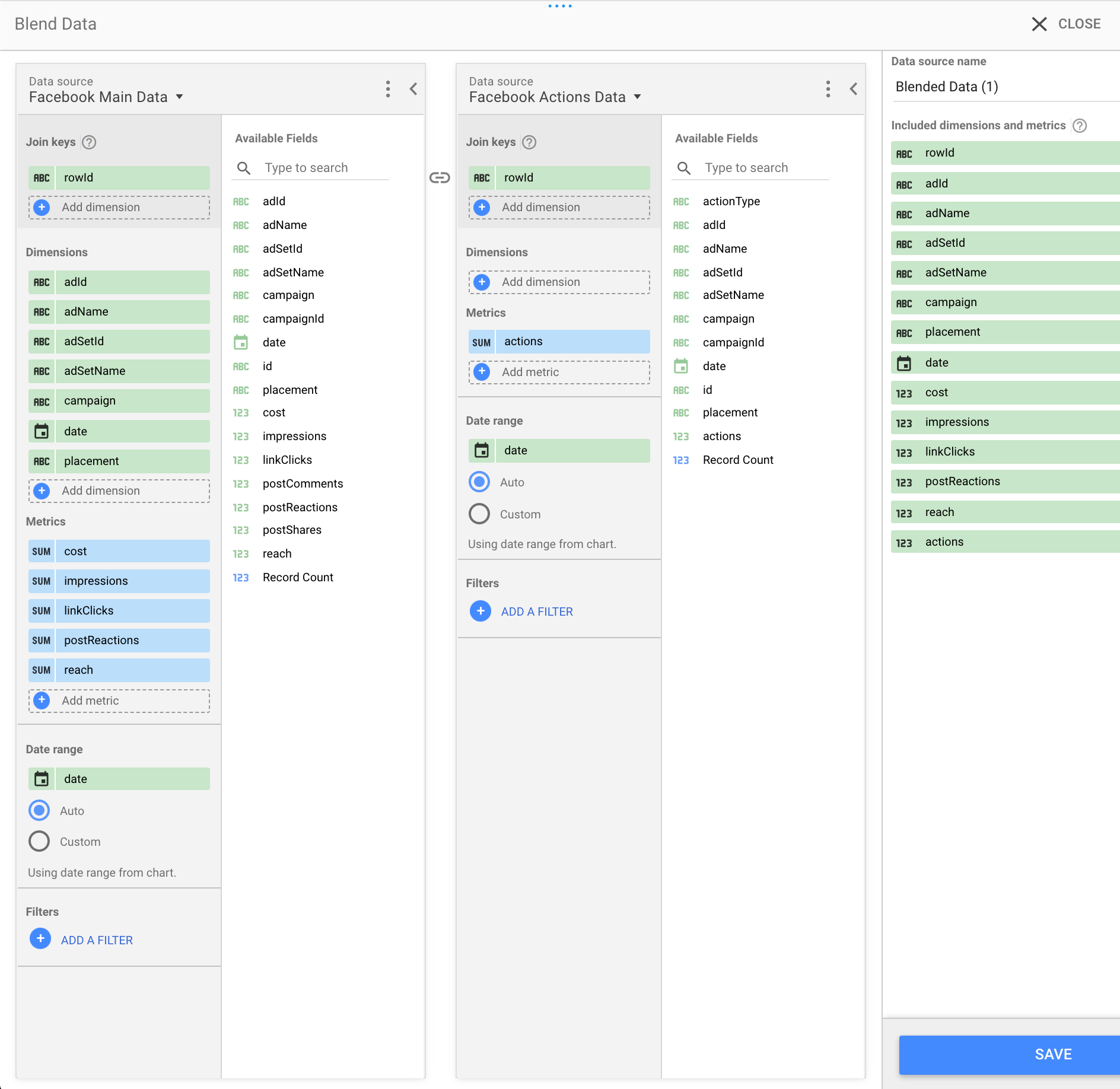 The benefit to knowing what is and is not compatible is that you will be able to accurately predict how many datasets you will need to generate, to build the dashboards to the client’s specifications. This will then enable you to forecast the hours you will require to complete the job.
The benefit to knowing what is and is not compatible is that you will be able to accurately predict how many datasets you will need to generate, to build the dashboards to the client’s specifications. This will then enable you to forecast the hours you will require to complete the job.
What should I report on?
Understanding what metrics and dimensions are available in the platform will give you a good idea of what the client expects. Remember, the client does not always know what they want, so being able to suggest relevant insights can be extremely valuable. While it is important to be able to report on what the client has asked, having the skills to reverse brief and validate client requirements is invaluable, and can save a lot of time.
Reverse briefing is beneficial as you can relay what you interpreted from the initial brief back to the client. This helps prevent any potential hiccups down the road if you had misinterpreted something early on.
Most marketing platforms revolve around user interaction, reporting on the below metrics:
- Impressions
- Clicks
- Conversions
- Click through rate (CTR)
- Viewability
Clients may also want to include demographic data to ascertain which genders and age groups are interacting most with their campaigns.
If you are targeting certain regions, geographic data can be very worthwhile. You can break down most platform data by:
- Continent
- Country
- State
- City
For social platforms, interactions with specific posts alongside demographic data will allow you to see which content is performing well amongst your target audience. Important Facebook engagement metrics include:
- Comments
- Page Likes
- Post Reactions
- Post Shares
While it is beneficial to gain insights on your audiences, and campaign performance, it is also important to monitor expenses. Running campaigns costs money, so analysing campaign spend is a great way to understand the actual value of a campaign to the company. Using the cost metric, you can calculate:
- Cost Per Click (CPC)
- Cost Per Thousand Impressions (CPM)
- Cost Per Conversion (CPA)
Now that we know what metrics are useful, how granular should the data be?
- Gather most data at a daily level. This way, you can always aggregate up to whatever you want if the client changes their mind later. There are some instances where this is not possible though, such as sites performance in Display & Video 360 (DV360), where you end up with thousands of rows of data even without a date field. In this case, I would suggest gathering data by week, but refreshing the data daily so you can see the progression as the week goes on.
-
Drill down to advertiser across other dimensions. This is often required by larger clients who may be running various advertisers for different arms of the company. The hierarchy would be:
Advertiser → Campaign → Ad → Ad Group → Creative
If in doubt, never be afraid to reach out to your colleagues for advice.
Documentation is life!
Okay, maybe it is not life… but it is important. Having an expansive and up to date knowledge base will enable your team to work consistently and follow processes easily. It will also help with onboarding new team members and bringing them up to speed. But what are the consequences of not having any documentation? A rogue developer can lead to messy codebases, poor version controlling, critical processes not being followed, and products being unintentionally broken.
Be consistent
Without consistency in the team, your codebase will not only look a mess, but will be confusing and difficult to navigate.
Naming conventions
Naming conventions allow for anyone in the team to understand the purpose of whatever they are looking at, so it is a imperative to develop sensible naming conventions for absolutely everything.
We use shorthand for many platforms that we draw data from, in order to shorten file names. Some examples of these are:
- fb - Facebook
- sa - Search Ads 360
- dv - Display & Video 360
- cm - Campaign Manager
- ga - Google Analytics
- gad - Google Ads
- aa - Adobe Analytics
Louder uses a filename structure that explains the content:
Client code - purpose of file - status of file → LOUD :: FB Conversion Data :: [MASTER].
The above example describes the file contents is the active Facebook conversions data for Louder.
For our BigQuery table connections to Data Studio, we incorporate:
Client code - dataset location - table name → dev_reporting.master_fb_conversions_data.loud.
From this, I know that it is a development table containing Facebook conversions data for Louder.
Coding standards
While some languages such as Python or YAML have strict rules on indentation, languages like SQL and HTML do not. Imposing coding standards across the team will allow for easy reading code all in one style.
Tools like EditorConfig can be used to control spacing in specific file types. For example, you can set tab to input 2 spaces in .sql files, but 4 spaces in .html files. This will help retain consistent indentation across a variety of file types. The rest is down to high quality and frequently updated documentation.
Internal processes
Having strict internal processes can be the difference between a bug being caught and a catastrophic failure in a product. That being said, if these processes are passed around by word of mouth, you will end up playing “telephone” with something that should never be misinterpreted.
My suggestions are:
- Keep internal processes documented in an easily accessible place
- Frequently update processes
- Hold retrospectives on processes that feel inefficient - it is likely they can be improved
Operationalise properly
Guaranteeing that the end product actually works is critical to a successful project. However, do not let the present blind you from the future, you should always aim for the product to continue working after handover. There are many ways you can ensure this happens and I will share my tips on nailing your operationalisation.
Talking to the client
There are a number of occasions where you might end up talking directly to the client. The most important conversations to have should be focused on requirements gathering and, if necessary, managing their expectations.
Requirements gathering
Understanding your client’s requirements is the key to a successful product launch, but this can often be the hardest part of the project. In some instances, the client may not even know what they want and in these cases, it is your responsibility to provide recommendations. The most effective way to do this is with a wireframe.
I would suggest using a tool such as Lucidchart to build out the wireframe. You do not need to put any real data into it, just design the dashboard layout. In each chart explain:
- Chart type
- Included data
- Data granularity
- Dimension filters
By building the wireframe without data, you’re able to go back and forth with the client on the design, without having to redesign datasets.
My recommendations are:
- Have one point of contact with the client for design - this helps prevent the client from sending conflicting ideas
- Understand the effort required based on the wireframe before you quote - you could be caught off guard if you don’t understand the compatibility of certain dimensions and metrics
- Get the data design signed off before you start building - the last thing you want is to have to start over to add in one extra dimension
Managing client expectations
Occasionally you will encounter a client that wants everything possible (and impossible) and they want it now. How do you make their expectations more realistic? Explain any platform limitations, such as Google Analytics not displaying any demographics rows with less than 10 hits. This should help the client to understand that going too granular is not always the best option.
In order to prioritise effectively and minimise unnecessary tasks, work with your client to assign each of their requested metrics and dimensions to MoSCoW. This development methodology aims to suitably prioritise tasks into four categories:
- Must have: essential items related to the product’s core functionality
- Should have: high priority items that are not critical to the product’s functionality
- Could have: medium priority items that may still cater to the high level functionality of the product, but will not be sorely missed if not included
- Would have: low priority items that will make minimal difference to the overall product
In order to provide a buffer and some extra time for unexpected issues and testing, I suggest overestimating the required hours by at least 15%.
Monitoring performance
Once you have launched your product, you must continue to monitor performance. Our industry is always evolving, and with this come changes to the tools we use. In some cases, these changes can be breaking, and without the proper action, your product will be left dead in the water.
Tests
Louder’s dev team are all advocates of test driven development. The principle of this method is every time you encounter an issue with your code, write a test that fails for that issue. obvious things to check include, same goes for any potential issues with your data. Some examples of tests would be to check the recency of the data, checking date formats, or checking for duplicated data.
Using dbt, you can automate these tests alongside your models. If you tag these tests, you can run them in a sensible order. For example, running data integrity tests before you compile the models, and data recency tests afterwards.
My advice for testing is:
- You can never run too many tests
- Write them as you develop your code, not afterwards
- Think about when these tests should be executed
Alerts
Utilising automated tests to check for issues is only half of the solution to performance monitoring. If you are unaware the test has failed, how do you expect to resolve the issue? This is where alerts come in. dbt Cloud has an email alert system for run failures that you can configure to notify you when your tests fail or when your models fail to run. The most sensible format for this is via your inbox.
Re-running models
The final thing to consider is how you re-run your models if they fail. Are you using the CLI, or their website’s UI? While anyone in the development team should be capable of using the CLI, perhaps your programmatic team need to refresh the data. Granting them access to the website will allow non technical members of your team to kick off a data refresh.
Learn from your mistakes
It is inevitable that at some point in your career, you will screw something up. Big or small, it is worth spending some time to understand what went wrong and how you can prevent the mistake in the future.
Hold retros on your mistakes
While not every error will require a retrospective session, some of the more significant ones would benefit from one.
Does it need a retro?
- Making a small typo in a test query ✗
- Accidentally deleting 6 months of data ✓
- Running untested code in production ✓
- Small bug slipping into production ✓
Why is this useful? It allows you to analyse the incident and understand what exactly went wrong, when, and why. You can use the information from this to help prevent similar mistakes from occurring.
Continually refine processes
As they say, hindsight is 20/20, so utilise the findings from your retro sessions to bolster your internal processes. Louder have utilised retrospectives in a number of ways, including the requirement of a reviewer for git pull requests. After a couple of occasions where irrelevant files were pushed into the Master branch, we held an informal retro on the issue. The result of this was the review system.
Let your mistakes refine you, not define you
Although it is important to learn from your mistakes, it is equally important not to get too caught up in them. While your colleagues may seem infallible, everyone makes mistakes (even management). So do not beat yourself up about it. Understand where you went wrong, incorporate those learnings into your processes and press on. You will be a far more experienced and well rounded developer in no time at all.
To conclude
[TL;DR]
While this is just a summary of my learnings over the last year, I would like to drive home the points I find most value in. So, remember:
- Whether you use any of the tools I talked about in this article or not, it is vital to understand the different features and applications of the tools you use. Being equipped with this knowledge can increase your productivity in many tasks, and even allow you to utilise your tools in unique ways.
- Learn the skills that surround your area of work. This will enable you to take some of the easier, more generalised workload away from specialists who could be better utilised.
- Poorly documented processes can lead to disaster. Inadequate coding standards will make code incredibly challenging to read and processes may be completed incorrectly, leading to issues in Git repositories or worse, problems with your products in production.
- Make sure you fully understand the scope and requirements of a project before you kick off. Doing this, will prevent time wasting due to misunderstandings down the road. You also need to ensure that your product continues to work it has been handed over to the client which, will leave you with a stable product, and a satisfied client.
- Hold retrospectives on any major mistakes. It will help you understand what went wrong and why and use the information to refine your processes. If you hold retros frequently and run them correctly, you should prevent your team from making the same mistake twice.
While I am certainly no expert in the field, I hope you are able to learn from my experiences utilise some of my suggestions. To the junior analytics engineers and data scientists reading this, I will leave you with one last piece of advice -
Stack Overflow is your best friend.

About
Sam Kenney
Sam is a software engineer. In his spare time he plays guitar for the UK-based alternative band, Worst Case Scenario.